Most of real world datasets have class imbalance, where a “majority” class dwarfs the “minority” samples. Typical examples are – identifying rare pathologies in medical diagnosis or flagging anomalous transactions to detect fraud or detecting sparse foreground objects from vast background objects in computer vision to name a few.
The machine learning models we have discussed – binary classification (refer post Gradients for Binary Classification with Sigmoid) or multiclass classification (refer post Gradients for multi class classification with Softmax) needs tweaks to learn from these imbalanced datasets. Without these adjustments, the models can “cheat” by favouring the majority class and can report a pseudo high accuracy though the class specific accuracy is low.
Different strategies have emerged over the years, and in this article we are covering the approaches listed below.
- Weighted cross entropy
- Foundational baseline, where a class-specific weight factor to the standard cross-entropy loss to weight the loss based on frequency of the class.
- Focal Loss for Dense Object Detection, Lin et al. (2017)
- Propose a modulating factor
to the cross-entropy loss to down-weight easy/frequent examples which indirectly forces the model to focus on hard/rare examples
- Propose a modulating factor
- Asymmetric Loss for Multi-Label Classification, Ridnik et al. (2021)
- Extended the intuition of Focal Loss by having independent
hyper-parameter for positive and negative samples. This allows for more aggressive “pushing” of easy/frequent examples while preserving the gradient signal for hard/rare samples.
- Additionally, authors introduces a probability margin that explicitly zeros out the loss from easy/frequent samples.
- Extended the intuition of Focal Loss by having independent
- Class-Balanced Loss Based on Effective Number of Samples, Cui et al. (CVPR 2019)
- Based on the intuition that there are similarities among the samples, authors propose a framework to capture the diminishing benefit when more datasamples are added to a class.
- Long-tail Learning via Logit Adjustment, Menon et al. (ICLR 2021)
- Based on the foundations from Bayes Rule, authors propose that adding a class dependent offset based on the prior probabilities help the model learn to minimise the balanced error rate (the average of error rates for each class) instead of minimising global error rate.
Weighted Cross Entropy
Standard Cross Entropy treats all classes equally, which becomes problematic when your dataset contains 1,000s of easy background examples but only 100s of rare foreground objects. In such cases, the majority class dominates the loss and biases the model. Weighted Cross Entropy (WCE) addresses this by assigning a static weight to each class, manually boosting the importance of rare samples.
Binary weighted Cross Entropy
For binary classification, a weighting factor to the standard BCE formula is used the scale the loss.
where is typically set to the inverse of the class frequency.
By setting a high for the rare class (e.g., 0.9 for the 100 foreground samples) and a low weight for the frequent class (0.1 for the 1,000 background samples), ensures that the rare foreground objects provide a sufficient gradient signal during training.
Multiclass Weighted Cross Entropy
In the multiclass case with classes, the loss for a single example where
is the ground-truth label is defined as:
Where is a fixed weight assigned to class
, typically calculated using the Inverse Class Frequency:
Weighted versions of cross entropy loss is natively supported in PyTorch library as :
- torch.nn.BCEWithLogitsLoss (refer) : using the argument pos_weight for the binary classification
- torch.nn.CrossEntropyLoss (refer) : using the argument weight for multiclass classification.
Toy example computing the loss using the manually vs PyTorch implementation @ loss_functions_for_class_imbalance/weighted_cross_entropy.ipynb
Focal Loss (Lin et al 2017)
In the paper Focal Loss for Dense Object Detection Lin et al. (2017) , authors propose an extension to standard Cross Entropy loss to focus training on hard/rare examples. The key intuition is that by adding a probability-dependent modulating factor to the loss, the contribution of easy/frequent examples (where the estimated probability is close to the truth) is down-weighted. This indirectly forces the training to focus specifically on the hard/rare examples.
Focal loss is defined as :
where,
represent the ground truth labels and
is the estimated probabilities
Note : The standard cross entropy loss for binary classification is
Gradients in standard Cross Entropy Loss
To understand how Focal Loss works, the gradient i.e. the derivative with respect to the model’s output logits, is explored. The model outputs a real number
number, which is converted to a probability
using the sigmoid function
.
Using the chain rule from calculus (refer wiki entry on Chain Rule), then the gradient of loss with respect
is found as – gradient of loss with respect to probabilty
multiplied with gradient of probability with respect to parameter
i.e.
For standard Cross Entropy loss, as derived in the post on Gradients for Binary Classification with Sigmoid, gradient is,
The gradient is linear and depends only on the error – this means an “easy/frequent” example (where the error is small, e.g., 0.1) when summed over large number of of easy examples still contributes to the loss and can overwhelm the training.
Gradients in Focal Loss
For computing the gradients with focal loss, let us define the ground truth labels and the model’s estimated probability
as :
where,
background class with 1000’s of easy/frequent examples
foreground class with 100’s of hard/rare examples
Taking the case of ,
Multiplying with ,
Sweeping the value of from 0 to 1 for
, the behaviour of the individual terms are as shown in the plot below.
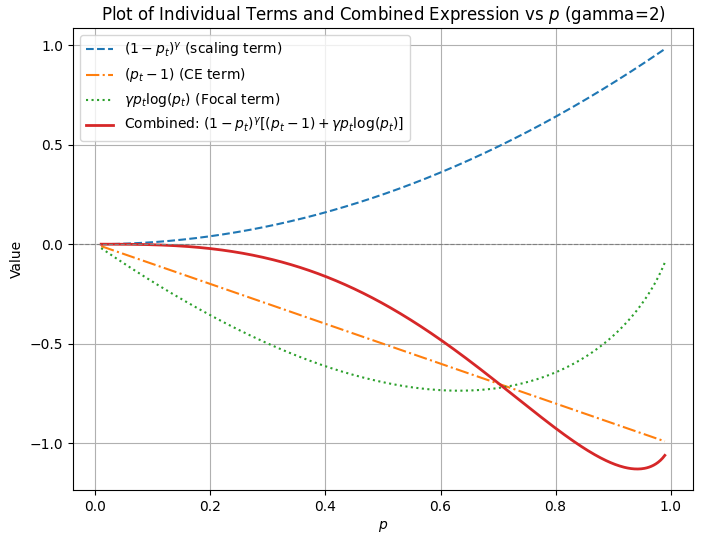
code @ focal_loss_terms.py
The model learns easy/frequent examples much faster and is close to the ground truth
, which means
. As
approaches 1, the scaling term
effectively silences the gradient.
Plugging in numbers, when the model is estimating for the frequent examples, the throttle becomes
and the gradient from these examples is effectively silenced.
Thus the term acts as a throttle for easy/frequent examples.
The Weighting Factor $\alpha$
With the focusing parameter down-weighting easy/frequent examples, the choosing class weights
parameter using inverse of class frequency is not preferred. To understand the intuitions, let us define
as below :
The Focal Loss including is :
When we go with inverse of class frequency, typically values of is :
- high
(around 0.9) for
- low
With the Focal Loss, the focusing term aggressively down-weights the easy examples and the accumulated loss from the background class drops drastically. Then with high
the hard/rare foreground class with only 100s of examples will now dominate the gradient and can cause instability.
Therefore, as is increased,
should be decreased. In the paper, for
, the authors found the best balance was actually
for the foreground class
.
Extension to Multiclass Focal Loss
While the binary case uses a single probability , the multiclass classification involve
distinct classes. In the multiclass setting, the model outputs a vector of logits, which are transformed into probabilities using the Softmax function. The estimated probability for
class is :
The Multiclass Focal Loss for a single example for ground truth class is,
Typically is chosen as a scalar, and the weights factor
is defined as a class dependent vector.
Choosing for the rare classes and
for the frequent classes seems to be choice which can be arrived at using hyper parameter tuning. Though it is counter intuitive to give higher
for frequent classes, it helps to prevent their contribution from being completely throttled by the
term.
Toy example showing implementation of Focal Loss for binary and multi-class classification @ loss_functions_for_class_imbalance/focal_loss_binary_multiclass.ipynb
Assymetric Loss (2021)
In the focal loss definition, the same is used for both background class with high count of easy examples and rare foreground class. If a higher
is used to throttle the gradients of easy background classes, then this also affects when the model is learning the hard foreground classes.
In the paper, Asymmetric Loss for Multi-Label Classification, Ridnik et al. (2021). authors proposed to decouple the for foreground and background classes.
To give emphasis to the contribution of positive samples, .
The typical values can be so that the hard/low count positive samples behave similar to standard cross entropy loss and
to throttle gradients for easy/high count background classes.
Authors further propose adding a margin on the probability of easy backround classes by probability shifting which discards them when the probability is below a threshold.
with as a hyperparameter and a typical value being
.
Combining both, the Assymetric Loss is defined as,
Toy implementation of assymetric loss @ loss_functions_for_class_imbalance/assymetric_loss.ipynb
Class-Balanced Loss (Yin Cui et al 2019)
In the paper Class-Balanced Loss Based on Effective Number of Samples, Cui et al. , authors argue that there will be similarities among the samples and as the number of samples increase, the probability that this sample is covered in the existing samples increases. Based on this intuition, authors propose a framework to capture the diminishing benefit when more datasamples are added to a class.
Derivation
Let us denote the effective number of samples as , and the total volume of this space as
. Consider the case where we have
examples and is going to sample the
example. The probability that the newly sampled example to be overlapped with the previous samples is,
Expected volume with the example is,
To solve for , re-writing as a geometric series,
For the general can be written as
Solving for ,
Note :
- When
, the effective number of samples
indicating that there is no benefit in adding more samples.
- When
, the expected number of samples
, indicating that each sample is treated unique.
In the paper authors explore as a hyper-parameter and report that in long tailed CIFAR-10 (Imbalance Factor = 50) dataset, the best is
. In this dataset, the most frequent class has 5000 images, while the rarest class has 100 images. With
, the effective number of samples for the frequent and rarest class is
| Weighting Scheme | β Value | Majority En | Minority En | Ratio (Maj/Min) |
| Inverse Frequency | 5000 | 100 | 50.0 : 1 | |
| Class-Balanced | 3934.85 | 99.5 | 39.5 : 1 | |
| Class-Balanced | 993 | 95.3 | 10.4 : 1 | |
| No Weighting | 1 | 1 | 1.0 : 1 |
Though the weight ratio between frequent class and small class is 50:1, by choosing a lower , we assume higher redundancy in the dataset and give lesser weightage to the sample count of majority class.
Applying to loss
To balance the loss, for each class which has
samples, a weighting factor
that is that is inversely proportional to the effective number of samples for each class is found out, i.e
.
To make the total loss roughly in the same scale when applying , a normalization factor to scale the sum of
to the class count
i.e.
With this definition,
a) the class balanced softmax loss is,
b) class balanced focal loss is,
Class-Balanced Loss as a specific weighting strategy for standard loss functions and it provides a mathematically grounded way to calculate the weight capturing the “effective number of samples“
Code to find the class balanced weights @ loss_functions_for_class_imbalance/class_balanced_weights.ipynb
Logit Adjustment (Menon et al 2021)
In the paper Long-tail Learning via Logit Adjustment, Menon et al. (ICLR 2021), authors argue that for scenarios with heavy class imbalance, the average misclassification error is not a suitable metric.
Average Classification error in Multiclass classification
Consider that is an
dimensional input feature vector
and the model is trained on a multiclass classification task to learn the probability of
classes.
The model outputs a vector
which captures the logarithm of the probability (aka logit) for each class. The scores are converted into probabilities using SoftMax function. For the class
, the estimated probability is,
Taking logarithm,
where, constant .
The training loop to estimate the probability of the true class given the input
, minimizes the negative log likelihood i.e.
From the above equation, we can see that – when the logit corresponding to true class is much greater than the logit corresponding to incorrect class
i.e.
, the exponential term
and the loss tends to 0.
To understand how the class imbalance affects the loss, the term can be expanded using Bayes rule (refer wiki entry) as,
If the classes are balanced, then the class frequency term tends to 0 and does not contribute to the loss. However, when there is class imbalance, for example with with the class
being rare, then the term
is a large positive number contributing to the loss.
To minimize the loss, instead of doing the “hard work” of learning discriminative features in the likelihood term , the model can “cheat” by biasing its predictions toward the majority class
.
Thus we can see that a model which minimizes the average misclassification error has its learning affected by the prior probabilities i.e. .
Logit Adjustment for Balanced Error rate
For a model to minimize the balanced error rate i.e. , the loss should depend only on the likelihood
and not be affected by the prior probabilities
.
This is can be done by dividing the posterior probabilities by the prior probabilities. This is equivalent to subtraction of the log prior for each class i.e
from the model
output capturing the log probabilities
.
Defining as the probability of each class
, the adjusted logit for each class is,
where, is a hyperparameter to tune.
: Theoretically aligns the model to minimize the balanced error rate, typically chosen value.
: Provides a partial correction, useful for balancing overall accuracy and per-class recall in noisy datasets
: Over-corrects for minority classes, pushing decision boundaries further to prioritize rare class recall
: Disables the adjustment, reverting the model to standard cross entropy loss.
The loss function with adjusting the logits is ,
Incorporating into the training loss, enforces a class-dependent margin. This forces the model to “work harder” on minority classes by requiring a higher logit score for a rare class to achieve the same loss as a majority class.
During inference, the adjustment is typically removed to use the raw learned likelihoods, resulting in a model that has learned to treat each class with equal importance regardless of its original frequency in the training set.
Example code with logit adjusted loss @ loss_functions_for_class_imbalance/logit_adjusted_loss.ipynb
Summary
This article covers :
Evolution: How we move beyond standard Cross Entropy to specialized loss functions like Focal Loss and Asymmetric Loss to handle extreme class imbalance.
Math: Detailed derivations of the gradients for Focal Loss and a Bayesian decomposition of Logit Adjustment to show how models “cheat” using prior probabilities.
Intuition: A look at the Effective Number of Samples framework, capturing the diminishing returns of adding more data to a majority class.
Code: Complete Python and PyTorch implementations, including toy examples and notebooks comparing manual derivations against library-standard functions.